Beyond Human Capability: The Robotic Era
October 2025
Foreword
The wave of embodied intelligence is sweeping the globe, reaching unprecedented visibility across academia and industry. Startups are springing up everywhere, converging on a shared vision—bringing AGI into the physical world. In this “first year of embodiment,” we focus on one core topic: deployment. We also introduce our latest result in real‑robot reinforcement learning—RL‑100.
We see dazzling robot demos every day—parkour, backflips, dancing, boxing. Impressive, yes—but what kind of robots do we actually need? We look forward to the day a robot can do laundry, make breakfast, and act as a reliable daily assistant. To reach that vision, we prioritize deployability metrics—reliability, efficiency, and robustness. No one wants a helper that breaks three plates while doing dishes or needs five hours to cook a meal. These metrics motivate this work and serve as our evaluation yardsticks.

Reinforcement learning has dazzled the world in milestones like AlphaGo and GPT. Yet the refrain—“RL is nothing for robotics”—persists. Why? In games or language, data is abundant (massive simulation, web text). In robotics, real‑world data is expensive and sim‑to‑real gaps are severe (dynamics, sensing—vision, touch). A data‑hungry method like RL struggles without careful system design.
Below, we outline the pros/cons of Imitation Learning (IL), Human‑in‑the‑Loop (HITL) augmentation, and Reinforcement Learning (RL)—and how to combine them.
Imitation Learning: Strengths and Ceiling
Learning from smart human priors speeds up robot onboarding. But high‑quality real data is scarce:
- Teleop bias: Sensing/control latency encourages slow, conservative motions and suboptimal trajectories.
- High collection cost: Large datasets need skilled operators—labor‑intensive and expensive.
- Coverage gaps: Limited high‑quality data yields incomplete state–action coverage, hurting generalization and reliability.
Thus, pure supervision faces a ceiling of imitation: performance is bounded by the demonstrator’s ability and inherits inefficiencies, biases, and occasional errors.
HITL Augmentation: Gains and Limits
Adding smart humans to patch IL is practical: use HITL or a world/reward model to identify weak regions of the policy’s state/trajectory distribution, then target data collection and fine‑tuning. This expands coverage and boosts generalization—essentially coverage + human correction to compensate for IL’s bottlenecks.
However, if a policy never experiences failure and relies mainly on external handholding, it won’t learn to avoid bad states. RL treats failure as a crucial learning signal: through interaction, exploration, and correction, the policy learns which behaviors push the system toward undesirable states—and how to act optimally within them. The goal isn’t to “fall into a bad distribution and then fix it,” but to avoid entering and amplifying those bad distributions. Also, IL is bounded by its dataset; truly superhuman robots must go beyond imitation.
Why RL—and What Blocks It
RL provides a complementary path: it optimizes return, not imitation error, and discovers strategies rare or absent in demos. Two blockers in robotics:
- Costly real‑world data: starting from scratch is sample‑inefficient.
- Sim‑to‑real gaps: differences in dynamics and perception (vision, touch, etc.).
A central question emerges: How do we leverage strong human priors and continually improve via self‑directed exploration? Consider how children learn to walk: guided by parents first, then autonomous practice until mastery across terrains. Likewise, a practical robot system should combine human priors with self‑improvement to reach—and surpass—human‑level reliability, efficiency, and robustness.

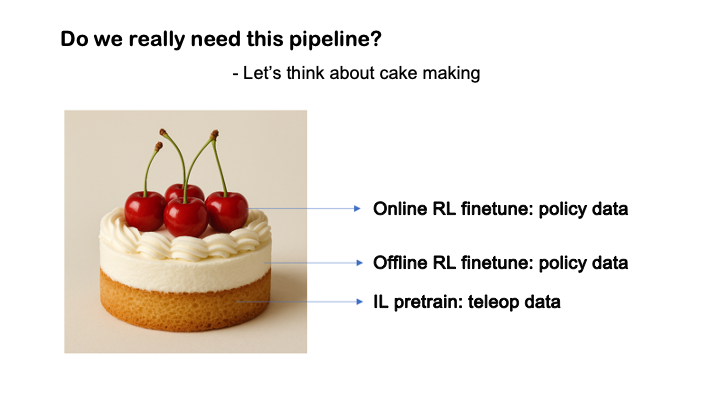
RL‑100: Learning Like Humans
We start with human priors—teachers “teach,” but students need self‑practice to generalize. RL‑100 adds real‑world RL post‑training on top of a diffusion‑policy IL backbone. It retains diffusion’s expressivity while using lightly guided exploration to optimize deployment metrics—success rate, efficiency, and robustness. In short: start from human, align with human‑grounded objectives, then go beyond human.
- IL pretraining: Teleop demos provide a low‑variance, stable starting point—the sponge layer of the cake.
- Iterative Offline RL post‑training: Update on a growing buffer of interaction data—the cream layer delivering major gains.
- Online RL post‑training: The last mile to remove rare failures—the cherry on top. A small, targeted budget pushes ~95% → 99%+.
RL‑100 Algorithmic Framework
We begin with Diffusion Policy (DP)‑based IL, which models multi‑modal, complex behavior distributions in demos. This is a powerful behavior prior for RL. On top of that, we apply objective‑aligned weighting and fine‑tuning so the policy learns when/where/why to choose better actions rather than replay frequent demo actions.
Because human data alone can’t cover the full state–action space, we place the policy in the real environment for trial‑and‑error and combine human data with policy data:
- Continue IL to absorb augmented behavioral modes.
- Run Iterative Offline RL on a rolling buffer of interactions to perform greedy, objective‑aligned fine‑tuning, steadily lifting the performance ceiling.
Online RL is precious and sensitive; we use it for the last mile, polishing ~95% to 99%+. With a unified offline–online objective, the transition is seamless and regression‑free.
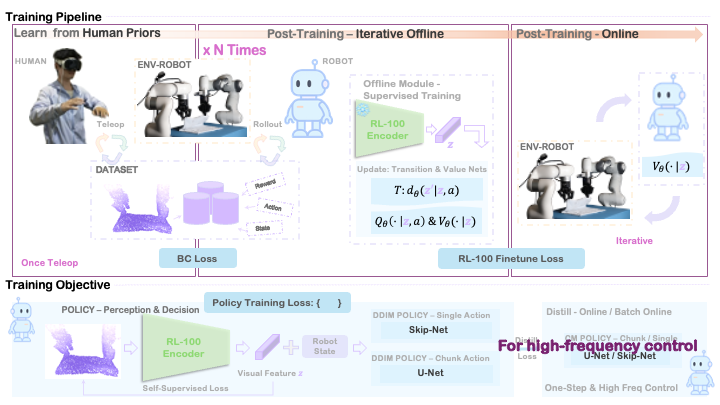

Key Modules — Takeaways
- Single‑step actions & action chunking: Single‑step excels in reactive tasks (e.g., dynamic bowling). Chunking reduces jitter for precision tasks (e.g., assembly). Both share one training scaffold for flexible deployment.
- One‑step Consistency Distillation: Enables high‑frequency control critical for industry. A single forward pass yields K‑fold speedups (e.g., 100 ms → 10 ms) while preserving diffusion‑policy quality, unlocking stable cycle time, conveyor tracking, and safe HRC.
Experiments
Main Results
7 real‑robot tasks, 900/900 total successes; 250 consecutive successes in a single task, >2 hours nonstop. Under physical disturbances, zero‑shot, and few‑shot adaptation, success remains high. An orange‑juicing robot provided 7 hours of continuous service in a mall with zero failures.



Robustness Under Human Disturbances
- Soft‑towel Folding: Disturbances in Stage‑1 (initial grasp) and Stage‑2 (pre‑fold) each retain 90% success.
- Dynamic Unscrewing: Up to 4 s of reverse force during twisting and critical visual alignment—100% success; stable recovery.
- Dynamic Push‑T: Multiple drag‑style disturbances during pushing—100% success.
Overall: 95.0% average success across tested scenarios, indicating reliable recovery under unstructured perturbations.
Zero‑Shot Generalization
- Dynamic Push‑T: Large friction changes—100%; added distractor shapes—80%.
- Agile Bowling: Floor property changes—100%.
- Pouring: Granular (nuts) → liquid (water)—90%.
Average 92.5% success across four change types without retraining.
Few‑Shot Generalization
- Soft‑towel Folding: New towel materials—100%.
- Agile Bowling: Inverted pin arrangement—100%.
- Pouring: New container geometry—60%.
Average 86.7% with only 1–3 hours of additional training.
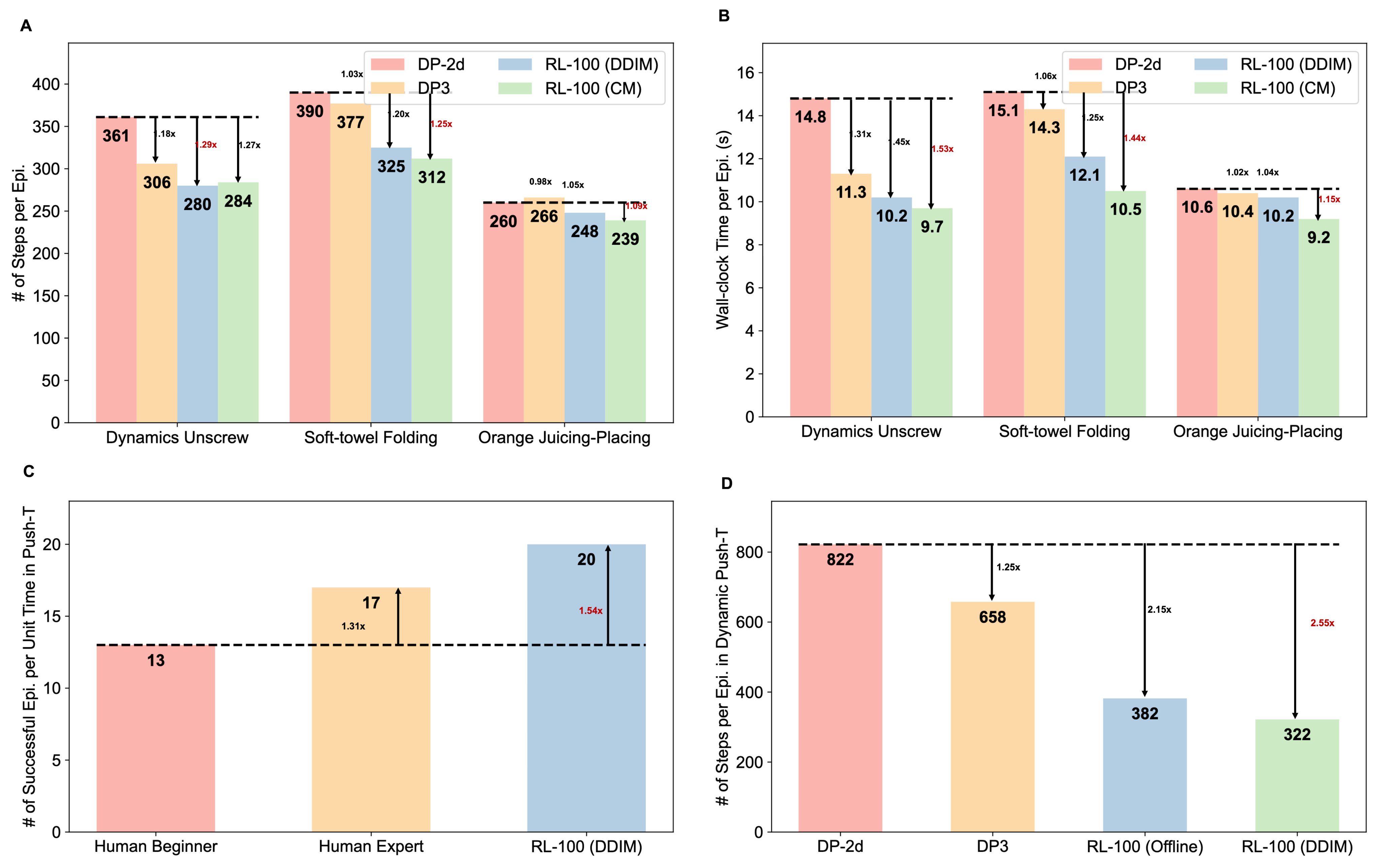
Efficiency vs. Baselines & Humans
- Steps in successful trajectories: Soft‑towel: 390 → 312 (×1.25); Unscrewing: 361 → 280 (×1.29).
- Wall‑clock per episode: RL‑100 (CM) one‑step vs. DDIM: 1.05–1.16× latency reduction; point clouds over RGB: 1.02–1.31×. Orange Juicing: 9.2s, 1.15× faster than DP‑2D.
- Versus humans (Dynamic Push‑T): 20 episodes/unit time, beating experts by 1.18×, novices by 1.54×—superhuman efficiency.
- Including failures: DP‑2D: 822 → RL‑100 DDIM: 322 (×2.55 reduction)—efficient and fast aborts.
Summary: Gains from (1) efficient encoding (point cloud > RGB), (2) reward‑driven optimization (γ < 1), (3) one‑step inference. Monotonic trend: DP‑2D → DP3 → RL‑100 DDIM → RL‑100 CM.
Robot vs. Humans — Bowling
Robot vs. 5 people: 25/25 vs. 14/25.

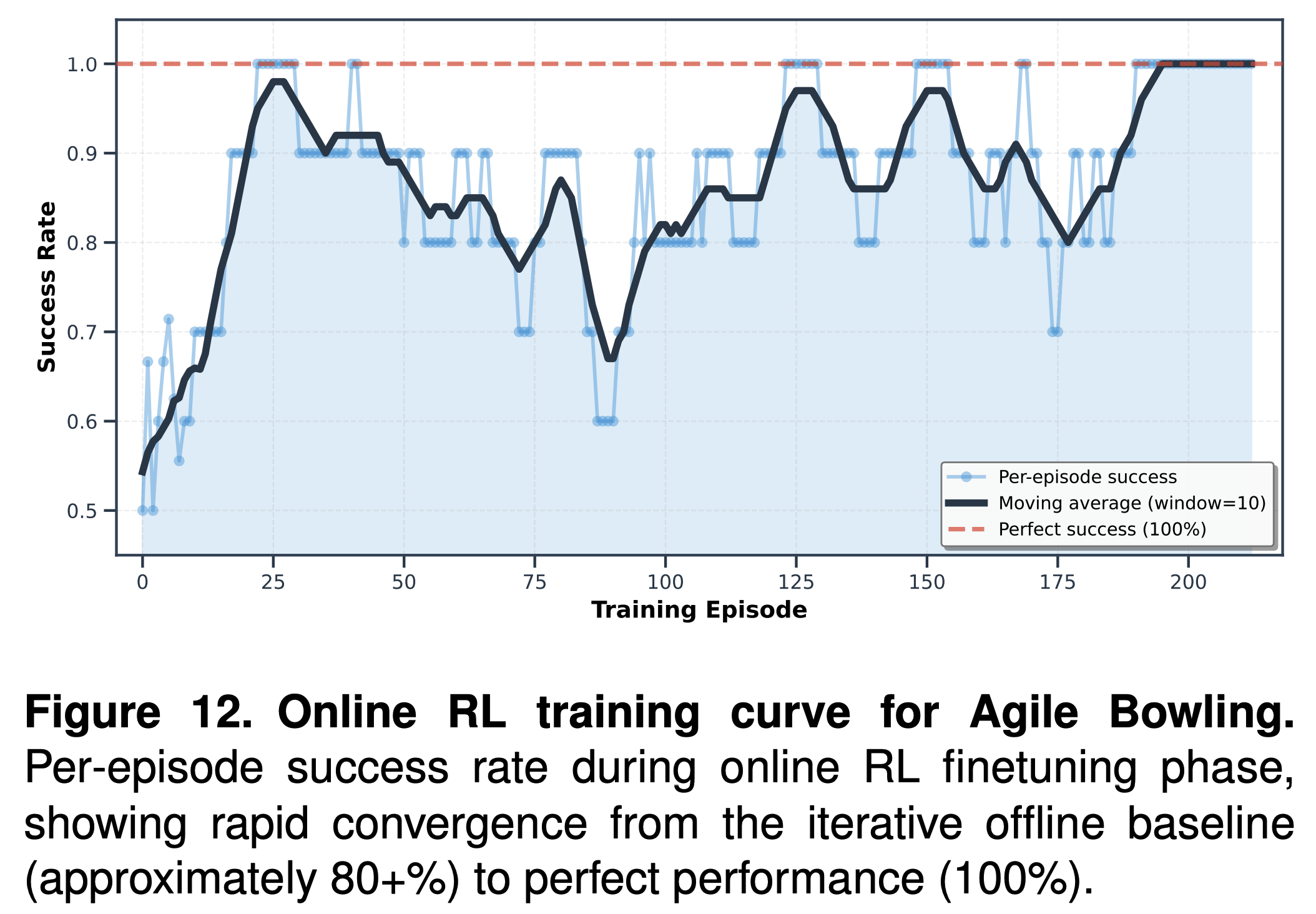
Training Efficiency
- ~120 on‑policy episodes to reach stable 100% success.
- Smooth learning with no offline→online regression.
- Last 100+ episodes maintain perfect success.
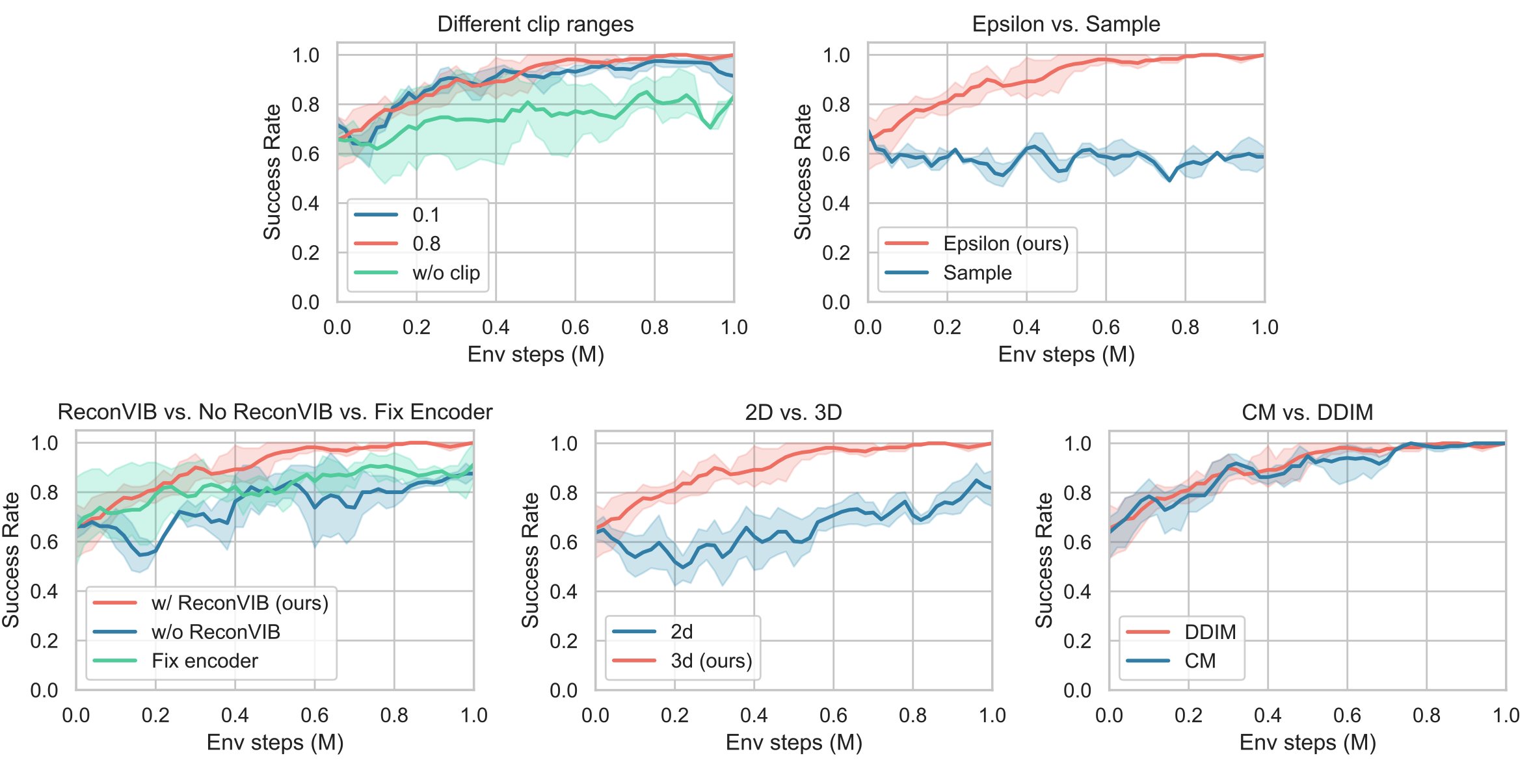
Ablations — Takeaways
- Variance clipping stabilizes exploration during stochastic DDIM sampling.
- Epsilon prediction fits RL better; larger noise schedules promote exploration.
- Reconstruction constraints mitigate representational drift, improving sample efficiency for vision‑based manipulation.
- 3D models learn faster and reach higher final success in clean scenes.
- Consistency Models (CM) compress multi‑step diffusion to one‑step without degrading control quality, enabling high‑frequency deployment.
Outlook
Next we will stress‑test in more complex, cluttered, partially observable settings—closer to homes and factories: dynamic multi‑object scenes, occlusions, reflective/transparent materials, lighting changes, and non‑fixed layouts. Building on near‑perfect success, long‑horizon stability, and near‑human efficiency, these tests will better reveal deployment limits and failure modes.
Small diffusion policies with modest fine‑tuning already achieve high reliability and efficiency. We plan to extend post‑training to multi‑task, multi‑robot, multi‑modal VLA models, including:
- Scaling laws for data/model size vs. real‑robot sample efficiency.
- Unified policies for cross‑embodiment and cross‑task transfer.
- Aligning large‑scale VLA priors with RL‑100’s unified objective to balance semantic generalization and high success.
Although the pipeline supports conservative operation and stable fine‑tuning, reset and recovery remain bottlenecks. We will explore autonomous reset mechanisms—learned reset policies, scripted recovery motions, task‑aware fixtures, and failure‑aware action chunking—to reduce human intervention, downtime, and stabilize online improvement—complementing RL‑100.